코드카타 오답노트
|
SELECT animal_id, name, date_format(datetime, '%Y-%m-%d') #date_format의 %뒤에 오는 값은 대소문자를 비교함
FROM animal_ins |
%Y = yyyy / %y=__yy %M = 숫자가 아닌 달이름(1월, 2월) / %m = mm %D = 숫자가 아닌 첫째, 둘째와 같이 출력(1st, 2nd) / %d = dd |
|
SELECT product_id, product_name, product_cd, category,price
FROM food_product WHERE price=(SELECT max(price) FROM food_product) #f테이블에서 가장 높은 price 컬럼을 선택하고, WHERE절로 price는 가장 높은 값만 필터 |
|
|
SELECT COUNT(*)
FROM user_info WHERE (joined >= '2021-01-01' and joined<'2022-01-01') and (age between 20 and 29) |
더 효율적임 SELECT COUNT(*)
FROM user_info where joined Like '2021%' |
|
SELECT animal_id, name,
case when (SEX_UPON_INTAKE LIKE 'Neutered%' or sex_upon_intake LIKE 'spayed%') then 'O' else 'X' end `중성화` # =말고 LIKE 쓰기 FROM animal_ins |
|
GROUP BY HAVING 정리

| SELECT * FROM books; books 테이블에서 전체 컬럼을 조회. |

| SELECT * FROM books GROUP BY genre; books 테이블에서 전체 컬럼을 조회. genre 컬럼을 중심으로 group. (사진에서 total이 아니라 qty) |

|
SELECT genre, SUM(qty) as total
FROM books GROUP BY genre; books 테이블에서 genre로 컬럼을 묶어 준 다음(위의 테이블 처럼) 각 그룹간의 qty을 더한 후 genre 값과 total값 출력 |
만약 여기서 HAVING을 추가하게 된다면
|
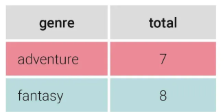
SELECT genre, SUM(qty) total
FROM books GROUP BY genre HAVING SUM(qty) >=7; 각 그룹별에서 합산된 total 값을 살펴보고 HAVING의 조건인 7, 8의 값을 갖는 fantasy와 adventure을 출력 |
그 외의 HAVING 조건을 걸었을 때의 결과값

| SELECT genre, count(*) as total FROM books GROUP BY genre HAVING count(*) >=2; 각 그룹마다 2 이상이기 때문에 모든 그룹이 출력 만약 HAVING count(*) >2이었다면 빈컬럼 출력(Null X) |
| SELECT genre, SUM(qty) FROM books WHERE qty > 1 GROUP BY genre HAVING SUM(qty) >=5; FROM : books 테이블에서 WHERE : qty가 1보다 큰 수를 먼저 찾음(romance에 있는 1값은 탈락) GROUP BY : genre로 값이 묶음 HAVING : 각 genre의 qty의 합을 구하고 ( adventure = 7, fantasy = 8, romance = 2) / 그 구한 값이 5 이상이면 선택 ( adventure = 7, fantasy = 8 ) SELECT : genre과 having에서 필터링된 값만 출력 |
| WHERE와 HAVING 차이점 WHERE 그룹화 이전에 데이터를 필터링 행 마다 WHERE의 조건을 필터 HAVING 그룹화 이후에 데이터를 필터링 그룹화 된!! 행끼리의 값을 SUM, AVG 한 뒤 그 값을 필터링 FROM - ON - JOIN - WHERE - GROUP BY - HAVING - SELECT - ORDER BY - LIMIT *GROUP BY의 결과값 = DISTINCT의 결과값* |
| ORDER BY RAND() RAND()는 행의 랜던한 값을 생성 (매 실행할 때마다 랜덤으로 바뀜) LIMIT 마지막 행에 사용하여 상위 값만 추출 |